
An often overlooked topic in kubernetes is network security. This is probably caused by the fact that perople just assume it is secure by default because it is new, and because of the Service concept. The standard way to expose a service running in a pod is to create a Service for it and then reference the service from the consuming pod using its name. The advantage of this is that the service has a DNS name and also provides a fixed IP towards consumers, regardless of how many pods are running for this service or whether pods get deleted and created. However, direct communication between pods is possible by default.
This exposes a serious security issue if this network access is not restricted. This is because it would allow lateral movement by a hacker from one pod to the next since all ports are open. In particular, also access to the kubernetes API service is not restricted and pods, by default (!), also contain the mounted secrets for the service account.
There is even a standard feature in kubernetes to query all services and their ports in a cluster. Just start a container that has dig and do the appropriate SRV dns request:
> kubectl run --rm -it --image tutum/dnsutils -- bash If you don't see a command prompt, try pressing enter. root@bash:/# dig -t SRV any.any.svc.cluster.local ; <<>> DiG 9.9.5-3ubuntu0.2-Ubuntu <<>> -t SRV any.any.svc.cluster.local ...snip... ;; ANSWER SECTION: any.any.svc.cluster.local. 30 IN SRV 0 4 9402 cert-manager.cert-manager.svc.cluster.local. any.any.svc.cluster.local. 30 IN SRV 0 4 80 httpd-reverse-proxy-mountainhoppers-nl.exposure.svc.cluster.local. any.any.svc.cluster.local. 30 IN SRV 0 4 80 kubernetes-dashboard.kubernetes-dashboard.svc.cluster.local. any.any.svc.cluster.local. 30 IN SRV 0 4 80 nginx-nginx-ingress.nginx.svc.cluster.local. ...snip...
Now, isn’t this a warm welcome for hackers? A full list of all running services,namespaces, and their ports. The ideal starting point for trying to hack a system.
Testing network communication within the cluster.
Before we do anything, it is good to look around in an un-secured cluster. Let us try to contact the nginx pod from another pod. First, we check which ports are open in the nginx containers:
kubectl get pods -n nginx -o yaml
and we see that ports 80, 443, 9113, and 8081 are all open. We also need to get the IP address of one of the nginx pods:
kubectl get pods -n nginx -o wide
Next, we can use an nmap command to check for open TCP ports:
nmap "$SERVERIP" -p "$PORT" -Pn
A similar check can be done to check for UDP ports:
nmap "$SERVERIP" -p "$PORT" -sU
If the output contains the stat open for the port than we are sure that it is open.
Next, we need a temporary container to run the nmap command in and we have a simple automated check that is run from within the kubernetes cluster.
kubectl run --rm -it -n $NAMESPACE --labels=app=porttesting --image instrumentisto/nmap --restart=Never nmapclient --command -- \
nmap "$SERVERIP" -p "$PORT" -Pn |
grep "$PORT.*open " # note the space after 'open'
The above command starts a container in a given namespace with the label app=porttesting, using a docker image that has nmap. The label can be used to delete the pod in case it somehow keeps on running (kubectl delete pod -l app=podtesting -A). The restart=Never option is there to ensure that kubernetes is not continuously restarting the container, because it should only run this command once. The grep at the end finally executes on the local host, so not in the container and provides an exit status 0 if the port is open and non-zero if it is not. This is a nice way to obtain an automated test. Substituting various namespaces, we see that the nginx port can be accessed from everywhere. See also the remark on debug containers at the end to support testing in already running pods.
Network policies: short intro
Network policies can be used to restrict network access within a cluster. The following rules determine how network policies work:
- By default network traffic is unrestricted. If at least one network policy matches a pod for egress, then network policies for egress that match the pod determine what egress traffic is allowed, similarly for ingress.
- There are only allow rules, and no deny rules. Basically, network policies add up. Each network policy describes a form of allowed traffic. If there are multiple network policies that match a pod then all the traffic described in these network policies is allowed. This means that the order in which network policies are applied is irrelevant.
- Network policies only apply to pods. If there is a Service that forwards port 80 to port 8080 of a pod, then, to allow traffic to service port 80, traffic to port 8080 of the pod must be allowed.
Basically, we want to achieve microsegmentation where only the required traffic is allowed.
Network policies can define ingress or egress rules or both and specify source pod selectors based on labels, and target addresses based on CIDRs, pod labels of pods in the same namespace, or namespace selectors describing all pods in a different namespace. For the latter, namespaces must be labeled because they are selected by label. For an ingress rule, access to a source pod is defined and for an egress rule, access to a target address is specified from a source pod. See network policy recipes for examples of network policies for specific cases.
The way to deny access is to define a default rule that allows nothing.
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: default-allow-nothing
namespace: wamblee-org
spec:
podSelector: {}
policyTypes:
- Ingress
- Egress
In the rule above, both egress and ingress traffic is specified using the policyTypes configuration and since no ports are defined, this network policy does not open any access. However, since all pods in the namespace are selected because of the podSelector, this means that it applies to all pods in the namespace and therefore, no ingress or egress traffic is allowed for all pods in the namespace. This also includes ingress from outside the cluster and from pods in other namespaces and egress to outside of the cluster and to pods in other namespaces.
This is a nice failsafe, since when refining network policies it may occur that as part of more specific pod selectors, some pods are not matched anymore which then inadvertently opens up access to these pods. This default rule prevents that.
This ‘allow nothing’ rule must be defined for all namespaces for which network access must be restricted since network policies are namespaced resources. Note that there is a policyTypes element. In general, it will work when you define a network policy and leave out the policyTypes. This is because the policy type is inferred. However, the rules are a bit weird as explained by the docs:
kubectl explain networkpolicy.spec.policyTypes
Without policyTypes, the policy types always include ingress and egress is only included if there are one or more egress rules. For network policies that include only Egress rules this is equivalent to policyTypes with only Egress if the Ingress traffic is by default already denied. This means you have to be careful when defining an egress rule for a pod for which you don’t want to have any ingress rules. This rule is weird because it always defaults to having an ingress policy type even if no ingress rule is specified. Things would be a lot clearer if policy type ingress would only be inferred if an ingress rule is defined.
The only case where you cannot leave out policy types is when you want to specify a default egress rule that allows no traffic. In that case there are no egress rules (or equivalently with egress: [] an empty array). In that case, you would only get policyTypes Ingress. This is why for the default rule, the policy types are specified.
Network policies: application
To apply network policies, we apply the default ‘allow nothing’ rule for every namespace so that we start from a principal of least privilege where nothing is allowed unless it is specifically allowed.
Next we need to look at the deployment picture below to see what network traffic is required:
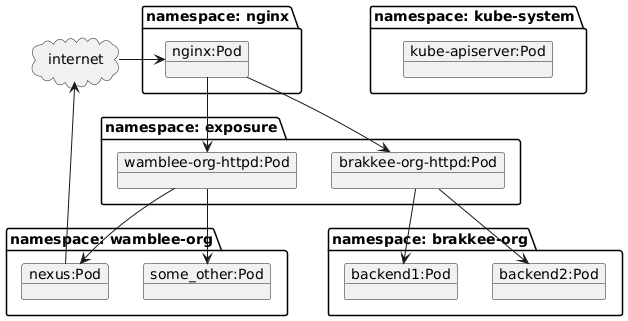
The deployment picture above is simplified, the services and ingress resources are omitted since network policies revolve around pods only. The ingress pods proxy traffic to the apache servers for the two domains running in the exposure namespace. These apache servers in turn proxy to pods running in the namespaces for these respective domains. For details on this setup, see my earlier post.
From the picture we obtain the following network rules:
- internet access
- traffic from the internet is allowed to nginx
- nexus is allowed to access the internet. This is required for proxying remote repositories although here more detailed rules can be defined for each remote repository
- nginx to exposure: Nginx may access the two pods in the exposure namespace. This can be realized by allowing access from all pods in the nginx namespace with the label app: nginx-nginx-ingress.
- nginx to the api-server: Nginx requires access to the API server to successfully startup.
- wamblee-org pods may be accessed from the wamblee-org-httpd pod. This is done based on the label
app:httpd-wamblee-org - brakkee-org pods may be accessed from the brakkee-org-httpd pod.
- system namespaces such as kube-system, may not be accessed from any of the shown pods. This rule is in fact enabled by default. Since we started with the default rule, this access is not allowed and if we don’t allow this access explicitly, then no access is possible.
Since we have the default ‘allow-nothing’ rule, we must both allow ingress and egress traffic for every allowed network communication. To simplify the setup we define the global communication topology in two steps:
- define Egress rules for access from one namespace to another to define the global communication topology
- define Ingress rules for each workload in a namespace using podSelector and (optionally) namespaceSelector that precisely define the allowed communication.
Internet access
Internet access to nginx is allowed using the following rule:
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: allow-http-https
namespace: nginx
spec:
podSelector: {}
ingress:
- ports:
- port: 80
- port: 443
from:
- ipBlock:
cidr: 0.0.0.0/0
except:
- 10.0.0.0/8
- 172.16.0.0/12
- 192.168.0.0/16
This defines a single rule that limits internet traffic to ports 80 and 443 from all public IP addresses by excluding local IP addresses. The above network policy has a single rule, but if you accidentally add a dash before the from keyword then there are two rules allowing all egress traffic to ports 80 and 443 or to any port on any public IP address.
Similarly for outgoing traffic from nexus, but here we also need to allow DNS queries to access external repositories by name:
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: external-internet-from-nexus
namespace: wamblee-org
spec:
podSelector:
matchLabels:
app: nexus-server
egress:
- ports:
- port: 80
- port: 443
to:
- ipBlock:
cidr: 0.0.0.0/0
except:
- 10.0.0.0/8
- 172.16.0.0/12
- 192.168.0.0/16
- ports:
- port: 53
protocol: UDP
- port: 53
protocol: TCP
API server access
Some pods may require access to the API server. One such example are the nginx pods that require this access for startup. There is no standardized way to do allow this access, however, therefore, we have to configure the IP CIDR of the api server (it listens on a node port of the controller) as well as the port. Usually, you know the address and port as part of defining the kubernetes cluster, but you also get it quickly using the following command which prints out the livenessProbe details of the API server pods:
> kubectl get pods -l component=kube-apiserver -o json | jq .items[].spec.containers[].livenessProbe.httpGet
{
"host": "192.168.178.123",
"path": "/livez",
"port": 6443,
"scheme": "HTTPS"
}
Next, we use an egress rule to allow access from nginx to the API server:
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: nginx-allow-api-server-access
namespace: nginx
spec:
podSelector: {}
policyTypes:
- Egress
egress:
- to:
- ipBlock:
cidr: 192.168.178.123/32
ports:
- port: 6443
Note that in my home setup, I am using a single controller node. Hence the /32 netmask.
Cross namespace access
For cross-namespace network policies we need to reference namespaces using labels, because they are selected by label. Kubernetes by default adds a label kubernetes.io/metadata.name to each namespace with the name of the namespace. Therefore, if you only want to reference a single namespace then that label can be used. It is more flexible though to label the namespaces yourself. To select namespaces we define a purpose label with values:
- web: nginx namespace
- exposure: the exposure namespaces
- domain: the namespaces related to the brakkee.org and wamblee.org domains
- system: any system namespace of kubernetes such as metallb-system, tigera-operator, calico-system, cert-manager, kube-node-lease, kube-system.
SImply use kubectl label –overwrite ns NAMESPACE app=VALUE to label a namespace.
We now have the following cross namespace rules for the exposure namespace allowing incoming traffic from nginx and outgoing traffic to the domain namespaces.
---
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: allow-egress-to-exposure
namespace: nginx
spec:
podSelector: {}
egress:
- to:
- namespaceSelector:
matchLabels:
purpose: exposure
---
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: allow-http-https
namespace: exposure
spec:
podSelector: {}
ingress:
- from:
- podSelector:
matchLabels:
app: nginx-nginx-ingress
namespaceSelector:
matchLabels:
purpose: web
---
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: allow-access-to-backends
namespace: exposure
spec:
podSelector: {}
egress:
- to:
- namespaceSelector:
matchLabels:
purpose: domain
Next, we allow ingress access to Nexus to ports 8081 and 8082
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: allow-nexus
namespace: wamblee-org
spec:
podSelector:
matchLabels:
app: nexus-server
ingress:
- ports:
- port: 8081
- port: 8082
from:
- podSelector:
matchLabels:
app: httpd-wamblee-org
namespaceSelector:
matchLabels:
purpose: exposure
With this setup, we have achieved microsegmentation where precisely the traffic that is required is allowed.
Service access from the exposure namespace
To allow service access using service names we must allow DNS queries like so:
---
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: allow-access-to-dns
namespace: exposure
spec:
podSelector: {}
egress:
- ports:
- port: 53
protocol: UDP
- port: 53
protocol: TCP
Other access
A final rule is required to allow access to a number of VMs since I am still migrating stuff to kubernetes and the migration is not complete. Therefore, sometimes, I am proxying traffic to specific VMs:
---
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: allow-access-to-vms
namespace: exposure
spec:
podSelector: {}
egress:
- ports:
- port: 80
- port: 443
to:
- ipBlock:
cidr: 192.168.178.123/32 # VM 1
- ipBlock:
cidr: 192.168.178.124/32 # VM 2
Final thoughts
Kubernetes by default allows unlimited network communication between pods. Traffic is only restricted by default when there is a network policy that matches a specific pod for ingress or pod for egress. This is unfortunate since it violates the principle of least privilege and is probably a left over of earlier kubernetes versions before network policies existed. The current way of working is then downwards compatible with these previous versions. I would like to see future kubernetes versions where default ‘allow nothing’ network policies would be active for new namespaces with additional network policies for the system namespaces.
There is certainly some redundancy in the rules for configuring similar things such as DNS access and internet access. This is screaming for a templating solution such as helm or jsonnet, or other tools (?). Also, there are tools available for enforcing certain policies in a kubernetes cluster (such as default ‘allow nothing’ rules).
In my experience, working with network policies is reliable and fast with the Calico network provider (I did not try any others). I refrained from using Calico-specific configurations, even if these are better (i.e. cluster wide policies). This way I can remain flexible w.r.t. the network provider I will use. Also, some cloud environments limit your choices or do not allow explicitly configuring a custom network provider, so in this way, anything I use is portable. Hopefully/no doubt, functionality from Calico and other network providers will trickle down into the standard APIs.
Finally, there is new functionality in kubernetes that allows containers to be added to a running pod (ephemeral containers). This functionality allows for testing network communication for already running pods. What I am aiming at here is a tool that allows testing of network policies using these debug containers, based on a compactly defined set of test rules. Such a tool would also allow the development of network policies. This is what I will be writing on in a future post.